Data Lake House on AWS, i.e. how to build a house on the lake of your data
Every organization collects or generates data regardless of its nature. To leverage the collective asset of the collected and generated data for operational and strategic purposes, a properly structured system is necessary. Data Lake House is one such data management and analytical concept.
In modern enterprise environments, solutions such as the data lakehouse AWS model provide a unified foundation for analytics, governance, and scalability, addressing challenges that arise from fragmented data platforms.
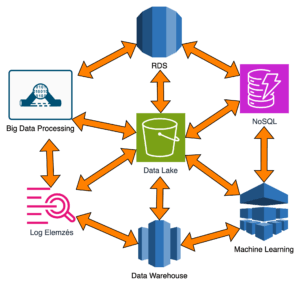
The Data Lake House architecture is born from the fusion of a data lake that supports machine learning algorithms prevalent in the corporate environment and “classic” data storage technology – Data Warehouse, aiming to exploit all their advantages.
This hybrid approach also aligns well with broader digital transformation initiatives, especially when organizations are planning large-scale cloud migration and need flexible yet governed data platforms.
What benefits do I get from it / Why is the Data Lake House good for me?
- The world is shifting from siloed data storage to “single-location” data storage (excluding recovery or backup data storage), so it’s worth keeping up with the world, modernizing, becoming innovative, and staying that way.
- By adopting an AWS data lake house approach, organizations can consolidate analytical workloads while maintaining openness and interoperability across data formats and tools.
- It allows for easy data movement between a data lake and purpose-specific / targeted data stores.
- It enables the versatile use of data, not isolating it from certain groups or multiple groups within the company. It can be understood as a form of data democratization. This democratization becomes even more valuable when advanced analytics and AWS AI services are layered on top of unified, well-governed datasets.
- Through the multiple representations/utilizations of data, data can be reused repeatedly, thanks to faster and more agile data movement and utilization.
- It provides a direct and combined opportunity for machine learning and analytical activities.
- Unified data management and access control can be implemented.
- Performance and cost-effective data loading can be achieved. It brings flexibility to the company’s operations.
- Logical Structure of the Data Lake House: The architecture’s layers are shown in the diagram below, which we will discuss and explore in more detail in the following subpoints.
The Logical Structure of the Data Lake House
The layers of the architecture, as seen in the diagram below, are outlined and explored in more detail in the upcoming subpoints. Understanding these layers is essential when building the data lakehouse, as each layer supports a specific responsibility in the overall analytical lifecycle.
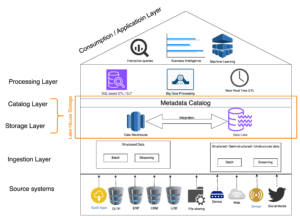
Data Sources / Source Systems
Data can come from numerous different sources, arriving in highly structured batches or in unstructured forms, within milliseconds or seconds (streaming). A well-designed Amazon data lake architecture ensures that these heterogeneous data sources can be ingested consistently while preserving data fidelity and lineage.
In the Data Lake House on AWS, in addition to operational sources (e.g., CRM, ERP systems), it is possible to manage data from web applications, social media, and IoT devices. The unified and coherent handling of data from these systems has the potential to enrich the data assets of a modern organization.
Ingestion Layer
Data enters the storage layer through the ingestion area of the Lake House, whether it originates from external or internal sources, regardless of protocol or data type. A robust data lakehouse implementation depends on this ingestion layer being scalable, fault-tolerant, and capable of handling both batch and streaming workloads. This makes the Lake House fully permeable in a holistic sense.
A foundation for this kind of permeability is established by AWS data acquisition services, including, but not limited to:
| Source Systems | Data Ingestion Services | Possible use cases |
| Operational Databases | Database Migration Service | Data movement between databases (on-prem to cloud) |
| SaaS applications | AppFlow | Data flow among applications |
| File servers | DataSync | File transfer |
| Streaming | Kinesis Firehose / Data Stream | Real time data gathering |
AWS Database Migration Service (DMS) is designed for migrating and synchronizing databases. Its main goal is to securely and efficiently move data between different database systems, whether it involves migrating databases from on-premises systems to AWS or synchronizing databases within AWS.
AppFlow enables secure and scalable data movement and synchronization between applications. With AWS AppFlow, data can be easily moved between different applications and services without the need for in-depth programming knowledge.
AWS DataSync allows for fast, secure, and automated data copying between various locations, such as on-premises systems and AWS storage. With DataSync, file-based data can be easily relocated and synchronized between on-premises data centers and AWS storage.
AWS Kinesis Firehose/Data Stream is designed for collecting and processing real or near-real-time data. Kinesis Streams allows for managing continuous data streams, while Kinesis Firehose simplifies the transmission of data to storage in AWS.
Storage Layer
The pillars of this layer are AWS data warehousing technology, Redshift, and Simple Storage Service (S3). Within the broader data lakehouse layers, the storage tier plays a critical role in balancing cost efficiency with query performance across different data consumption patterns.
Redshift provides storage for curated data in a standardized dimensional schema, but it also allows for the storage of semi-structured data. S3 serves as a home for exabyte-scale “lake” for structured, semi-structured, and unstructured data. It is advantageous to keep data in S3 in an open file format (accessible without proprietary software).
Redshift Spectrum is part of the Amazon Redshift data warehousing cloud service, enabling users to directly query and integrate data in Amazon S3 with Amazon Redshift data using SQL (Structured Query Language). With Redshift Spectrum, the following possibilities arise:
- Retaining a large amount of historical data in the data lake and copying only the necessary portion, e.g., a few months, to Redshift data warehouse disks.
- Enriching data stored in the lake or data warehouse without data movement.
- Inserting enriched datasets into Redshift data warehouse tables or external tables looking into the data lake.
- Pouring a large quantity of data into a more cost-effective storage service (e.g., S3 – Deep Archive) based on the data lifecycle.
As mentioned earlier, “S3 serves as a home for exabyte-scale ‘lake’ for structured, semi-structured, and unstructured data.” This layered storage strategy is a cornerstone of lakehouse architecture AWS designs, enabling seamless transitions between raw data storage and analytical consumption. The data in the lake buckets is organized based on the state and intention behind usage during data processing:
- Landing: Data from source systems is placed here without transformations. The processing process validates the data after landing in the landing bucket.
- Raw: Data enters this bucket upon successful processing and validation.
- Trusted: After transformations from the raw layer, individual files find their place in this trusted bucket.
- Curated: The conformant data/files in this bucket or phase are suitable for data modeling, and from here, they can be loaded into Redshift (e.g., for creating analytical analyses).
The storage and partitioning of data in any zone or bucket are determined by the usage mode associated with that layer. It is advisable to store files in open-source compressed formats (GZIP, BZIP, SNAPPY) to make storage more cost-effective and reduce reading speed. The latter is particularly significant in the Data Lakehouse data processing and consumer/application layers.
Catalog Layer
The central data catalog contains metadata for every dataset in the lake house, regardless of whether they are in data lake or data warehouse storage components. A centralized catalog also simplifies governance and compliance, which is particularly important when operating under enterprise-grade cloud managed services models.
Centralized metadata management makes data versioning and searchability across the entire spectrum of the analytics platform easier, facilitating schema-on-read data processing and usage. In this context, metadata includes not only technical attributes but also business attributes, such as the data’s sensitivity level.
Processing Layer
Perhaps the most versatile layer of the lake house, various transformations, whether technical or business, are implemented here. Efficient processing pipelines ensure that curated datasets are consistently available for analytics, reporting, and downstream applications without unnecessary duplication.
This layer turns raw data into consumable, informative data for the user (making numbers and letters collectively suitable for data-driven/assisted decision-making). The choice of AWS service(s) for data processing procedures is greatly influenced by the nature of the data (structured or not, hierarchical or not) and its flow speed.
SQL-Based Processing – Redshift
Massively Parallel Processing (MPP) is a database and data warehousing technology approach that uses multiple processors and storages for high-speed and efficient data processing. Redshift employs this approach. MPP architecture breaks down data processing tasks into different parts and executes them in parallel on multiple processors or nodes.
The discussed processing method is characterized by the following:
- Nodes and Segments: Amazon Redshift is an MPP data warehouse consisting of nodes. Each node is responsible for a subtask and a segment of the data. MPP allows the data warehouse to work on multiple tasks simultaneously since each node deals with its own segment.
- Distributed Data Storage: Amazon Redshift stores data in a distributed manner among nodes. This means that data is stored on different nodes, allowing queries and processing tasks to be performed in parallel.
- Inter-segment Parity: In MPP systems, inter-segment parity and balance help ensure an even distribution of the load among nodes. Additionally, thanks to parallel processing, data handling is more efficient and faster.
- Parallel Queries: Amazon Redshift allows parallel queries executed on each node simultaneously, increasing query performance, especially for large datasets.
Data warehouses employing MPP principles, like Amazon Redshift, are excellent for rapid and efficient processing of large amounts of data, making them ideal for analytical and business intelligence tasks.
Big Data Processing – EMR (Elastic Map Reduce) or Glue
The combination of AWS Glue and Elastic MapReduce (EMR) can be applied for data processing. AWS Glue is a fully managed data processing service that facilitates integration between data sources and data preparation in the Data Lake House. With Glue, the schema transformation and linkage logic of data sources can be easily defined, enabling data cleansing and structuring.
EMR provides flexible and scalable infrastructure through the creation of ‘instance fleets.’ Using the Hadoop Distributed File System (HDFS) and Spark framework, EMR enables parallel processing, resulting in efficient data processing, whether the data comes from S3 or Redshift. EMR creates clusters that scale based on the volume of data and processing needs.
By combining AWS Glue and EMR, data can be easily moved and processed. Glue aids in structuring, cataloging, and preparing data during the integration and preparation of data sources, while EMR’s flexible infrastructure allows for larger-scale data processing and data preparation for machine learning algorithms.
Streaming Processing – Kinesis
This processing method is necessary when large volumes (not large sizes) of data need to be validated, cleaned, enriched, or directly loaded into the lake house consumer layer in real-time, i.e., streamed.
It is possible to integrate data in near-real-time from sources to any layer of the lake house by combining Kinesis Data Stream, Kinesis Firehose, and Kinesis Analytics services with the previously mentioned or discussed EMR, Glue, Redshift services. This integration is achieved through interfaces that ensure data flows seamlessly.
Kinesis Data Streams are responsible for continuous data collection and parallel processing, while Kinesis Firehose automates the forwarding and transformation of data to desired storage locations.
Consumer / Application Layer
The benefits of data democratization within the organization, as mentioned in the architecture, manifest in the consumer or so-called application layer. This is where business value is ultimately realized, leveraging insights generated across the AWS lake house environment. It covers use cases for various user groups within the company, whether it be business intelligence (BI) or machine learning (ML). In this layer, AWS services are used to seamlessly traverse the lake house for relational, structured, and partially structured data storage formats (AVRO, Parquet, ORC, JSON), independent of the data’s storage format.
Interactive Queries
With Redshift, along with Redshift Spectrum, and Athena, data stored in S3 can be easily queried because both services share the same metadata catalog.
Athena is a serverless service whose cost is determined by the amount of queried data. It allows querying cataloged data without the need to load any amount into a database. Querying without data movement is facilitated by the common metadata catalog, providing the capability to join normalized relational data in Redshift with records found in operational databases.
Redshift can also execute queries similarly, but it is designed and implemented for different purposes. It is primarily used for resource-intensive analytical processes (OLAP). It provides the possibility of caching complex queries and parallel scaling. As long as the performance requirements of queries are unknown, it might be worthwhile to use its serverless instance.
Machine Learning
The DLH provides space for data scientists of advanced analytics companies to prepare training datasets jointly from the previously mentioned storage layers.
- Using the metadata catalog.
- Discovering datasets with Redshift and Athena queries.
- Combining and transforming with the EMR (Spark) service.
After transformations, the training data produced can initiate the application of machine learning algorithms in SageMaker. SageMaker includes widely used frameworks such as TensorFlow, MXNet, PyTorch, Keras, etc. In addition to built-in models, custom solutions can also be applied.
Business Intelligence
Information can be extracted from data through dashboard visualized analyses. It can be easily integrated with the previously mentioned SageMaker machine learning platform, enriching some visualized analyses with additional information. Visualized data can be displayed with QuickSight natively in AWS and embedded in various websites and applications.
Thanks to its scalable “in-memory” cache, it can scale to tens of thousands of users. Equipped with machine learning, it incorporates predictive and anomaly detection models.
How to proceed / How to start with the construction?
Building a Data Lakehouse on the AWS platform involves several steps. Successful projects typically begin with a clear architectural vision that aligns technology choices with long-term analytical and organizational goals. Below are the fundamental steps that can assist in implementing a Data Lakehouse on the AWS cloud platform:
1.Definition of Requirements and Objectives:
- Identification of business requirements and objectives aimed at achieving an analytics platform.
- Determination of data sources, data structures, and the type of data processing required.
2. AWS Account and IAM Users Management:
- Planning the development environment and network separations.
- Designing Access Management, including user roles and permissions for secure data handling.
3. Data Storage Planning:
- Selecting data storage solutions on AWS, such as Amazon S3, which is ideal for a Data Lakehouse.
- Structuring the data storage system, for example, with folder structures or data partitioning for organizing data.
4. Data Collection and Ingestion:
- Integrating source systems for continuous data collection and ingestion using data input services like AWS Kinesis Data Streams or Kinesis Firehose.
- Configuring data collection based on the frequency with which data needs to be gathered.
5. Data Transformation and Preparation:
- Automated transformation and preparation of data using AWS Glue service.
- Tasks in this step include modifying data schema, data cleansing, and database indexing.
- Implementation of an industry-specific data model.
6. Data Consumption and Analysis:
- Using Amazon Athena, Redshift, or QuickSight for querying and analyzing data.
- Configuring data loads for real-time data processing with AWS Kinesis service.
7. Automation and Monitoring:
- Automating and maintaining data processes using other AWS services, such as Step Functions or Lambda.
- Monitoring data processes with AWS CloudWatch and other monitoring tools (e.g., CloudTrail) for data quality tracking.
8. Security and Access Management:
- Establishing necessary security measures, including access control, encryption, and auditing.
- Covering AWS Identity and Access Management (IAM) permissions for data protection. This is a crucial aspect of a modern analytics platform, requiring careful attention to authorization, data access management, and monitoring.
9. Documentation and Training:
- Documenting Data Lakehouse architecture and operational processes in written form.
- Organizing training sessions for user groups on the use of AWS services, latest procedures, and best practices to enhance business continuity.
Wrap-Up
In the discussed chapters, a bird’s-eye view was presented on a modern analytics architectural approach, covering the possibilities of data ingestion, transformation, and utilization on AWS (without claiming completeness).
When designed correctly, a data lakehouse AWS solution provides the flexibility to scale from small analytical workloads to enterprise-wide platforms without architectural rework.
If in the future the organization plans or considers undergoing digital and analytical transformation, the Data Lake House approach should be considered if you want:
- An integrated and automatable platform, thereby achieving minimal implementation risk and a short “time to market.”
- A solution that can be started small, is serverless, has minimal costs, and can scale massively and immediately, adapting to the resource requirements of data loads.
- Access to a variety of services, flexible, innovative, and the ability to quickly reach new industry trends.
Layers can be created regardless of the size of the company, thanks to flexible scalability. The devil is in the details, and the technical or user/business logic behind the showcased services is where the complexity lies.
In case you need support or help with your implementation, please contact us at info@tc2.ai. We can help you plan, implement, migrate or participate in greenfield projects.
