Data Lake House AWS-en, azaz hogyan építs házat adataid tavára
Minden szervezet gyűjt vagy generál adatokat azok jellegétől függetlenül. Ahhoz, hogy a gyűjtött és generált adatainak együtteséből keletkezett adatvagyont működési és stratégiai céljainak érdekében hasznosítsa, annak megfelelően felépített rendszer szükséges. A "Data Lake House" egy ilyen adatkezelési és analitikai koncepció.
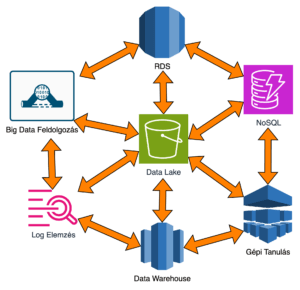
A Data Lake House architektúra a vállalati környezetben elterjedt gépi tanuló algoritmusok támogatását szolgáló data lake-ből és “klasszikus” adattárolási technológia – Data Warehouse – összeolvasztásából jött létre igyekezve kiaknázni azok minden előnyét.
Milyen előnyöm származik belőle / Miért jó nekem a Data Lake House?
- A világ tolódik el a silós adattárolástól “egyetlen helyszínű” adattárolásig (ide nem értendőek a recovery vagy backup adattárolások), tehát érdemes lépést tartani a világgal, korszerűsödni, innovatívvá válni ill annak maradni.
- Könnyű adatmozgatást hozhatunk vele létre data lake és célirányos / célzott adattárolók között.
- Adat sokrétű felhasználhatóságát teszi lehetővé, nem zárja el azt a vállalat egyes vagy több csoportjától. Egyfajta adat demokratizációként is érthető.
- Az adatok több vetületben történő ábrázolása / felhasználhatósága által az adatokat újra és újra hasznosíthatók a gyorsabb és agilisebb adatmozgatásnak, felhasználásnak köszönhetően.
- Gépi tanítás és elemzési tevékenységek közvetlen és együttes lehetőségét teremti meg.
- Egységes adatkezlést és hozzáférés-szabályozás vitelezhető ki.
- Teljesítmény és költséghatékony adattöltéseket érhetünk el.
- Rugalmasságot nyer vele a vállalat működése
A Data Lake House Logikai Felépítése
Az alábbi ábrán láthatók azon rétegei a szóbanforgó architektúrának, melyet az elkövetkezendő alpontokban számbaveszünk és részletesebben körbejárunk.
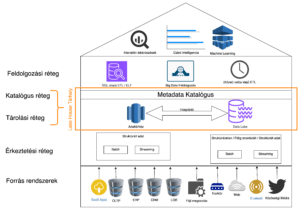
Adatforrások / Forrás rendszerek
Számos különböző forrásból érkezhetnek adatok erősen struktúrált formában kötegelve (batch) vagy struktúrálatlanul (unstructured), mikro-másodpercek, másodpercek alatt (streaming). Data Lake House-ba AWS-en belüli adatforrások mellett lehetőség van az operatív forrásokon (pl. CRM, ERP rendszereken) túlmenően web applikációkból, közösségi médiából és IoT eszközökből származó adatokkal is gazdálkodni. Ezen rendszerekből származó adatok együttes és egységes kezelése gazdagítani képes egy modern szervezet adatvagyonát.
Érkeztetési réteg
A Lake House érkeztetési (ingestion) területén keresztül kerül be az adat a tárolási rétegbe, jöjjön az külső vagy belső forrásból, protokolltól, adat természetétől függetlenül. Holisztikus vetületben teljesen átjárhatóvá téve a lake house-t.
AWS adatfelvételi szolgáltatásai teremtik meg ennek a fajta átjárhatóság alapját a következőkkel, a teljesség igénye nélkül:
| Forrás rendszerek | Adatfelvételi szolgáltatás | Lehetséges alkalmazási esetek |
| Operációs adatbázisok | Database Migration Service | Adatábzisrendszerek közötti adatmozgatás (on-prem to cloud) |
| SaaS alkalmazások | AppFlow | Applikációk közötti adatáramoltatás |
| Fájl szerver | DataSync | Fájl alapú kommunikáció esetére |
| Streaming | Kinesis Firehose / Data Stream | Valósidejű adatgyűjtésre |
AWS Database Migration Service (DMS) az adatbázisok migrálásához és szinkronizálásához terveztek. A fő célja az adatok biztonságos és hatékony mozgatása különböző adatbázisrendszerek között, legyen szó az adatbázisok migrálásáról az on-premises rendszerekről az AWS-be, vagy az AWS-beni adatbázisok közötti szinkronizációról.
Az AppFlow az alkalmazások közötti biztonságos és skálázható adatmozgatást és -szinkronizációt teremti meg. Az AWS AppFlow segítségével könnyedén lehet adatokat mozgatni különböző alkalmazások és szolgáltatások között anélkül, hogy mélyreható programozói ismeretekre lenne szükség.
Az AWS DataSync szolgáltatás lehetővé teszi adatok gyors, biztonságos és automatizált másolását különböző helyek között, például on-premises rendszerek és az AWS tárhelyek között. A DataSync segítségével könnyen lehet fájl alapú adatokat áthelyezni és szinkronizálni a helyi adatközpontok és az AWS tárhelyek között.
AWS Kinesis Firehose / Data Stream a valós vagy közel valós idejű adatok gyűjtésére és feldolgozására jött létre. A Kinesis Streams lehetővé teszi a folyamatos adatáramlások kezelését, míg a Kinesis Firehose egyszerűsíti az adatok továbbítását az AWS-ben lévő tárolókhoz.
Tárolási réteg
Ennek a rétegnek a pillére az AWS adattárház technológiája a Redshift és a Simple Storage Service (S3). Redshift az úgynevezett kezelt (curated) adatoknak biztosítja a tárolását sztandardizált dimenzionált sémában, azonban Redshift-ben van lehetőség féligstruktúrált adatok tárolására is. Az S3 ad otthont exabyte léptékű “lake”-ben struktúrált, félig struktúrált és struktúrálatlan adatoknak. Az adatokat S3-ban nyílt fájl formátumban (szabadon hozzáférhető formátum, és nincs szükség proprietárius szoftverekre az ilyen fájlok kezeléséhez) előnyös tartani.
Redshift Spectrum az Amazon Redshift adattárház felhőszolgáltatás része, amely lehetővé teszi a felhasználóknak, hogy az Amazon Simple Storage Service (Amazon S3) tárolóban lévő adatokat közvetlenül kérdezze le és integrálja az Amazon Redshift adatokkal SQL-ben (Structured Query Language-ben). A Redshift Spectrum használatával a következőkre is lehetőségünk adódik:
- Nagymennyiségű historikus adatot a “data lake”-ben tartani és az éppen szükséges pl. pár hónapnyit a Redshfit adattárház lemezeire másolni
- Adatmozgatás nélkül dúsítani a lake-ben vagy adattárházban tartott adatokat.
- Dúsított adathalmazt beszúrni Redshift adattárház táblájába vagy a data lake –re néző externál táblába
- Adatok használati életciklusának megfelelően nagy mennyiséget “kiönteni” egy költséghatékonyabb tárolási szolgáltatásba (pl. S3 – Deep Archive)
Ahogy korábbi sorokban megjelent az ” S3 ad otthon exabyte léptékű “lake”-ben struktúrált, félig struktúrált és struktúrálatlan adatoknak”. A lake bucket-ekbe rendezendők attól függően, hogy az adatfeldolgozás során milyen állapotú illetve milyen szándék áll a felhasználás mögött:
- Landing: forrásrendszerekből kerülnek ide az adatok transzformációk nélkül. A feldolgozási folyamat validálja az adatokat a landing bucket-be kerülés után.
- Raw: Sikeres feldolgozási folyamat és validáció esetén kerülnek ebbe a bucket-be az adatok.
- Trusted: A raw rétegből transzformációkat követően kerülnek ebbe (trusted) bucket-be az egyes állományok.
- Curated: A komformált adatok / állományok ezen bucket-ben vagy fázisban adatmodellezésre alkalmasak, így innen kerülhetnek betöltésre Redshift-be (pl. Analítikus elemzések létrehozására)
Az adatok tárolását és partícionálását bármely zónában vagy bucket-ben az adott réteghez fűződő felhasználás módja határozza meg. Az elhelyezett állományokat nyílt forráskódú tömörített formátumokban (GZIP, BZIP, SNAPPY) érdemes tartani. Ezzel a megközelítéssel tárolás költséghatékonnyabbá válik és az olvasási sebesség is csökken. Utóbbi leginkább a Data Lake House adatfeldolgozó és fogyasztói / applikációs rétegeiben válik jelentőssé.
Katalógus réteg
A központi adatkatalógus a lake house minden adathalmazának metaadatát tartalmazza függetlenül attól, hogy az a data lake vagy a data warehouse tároló komponensekben találhatók. Központosított metaadat kezeléssel könnyebbé válik az adatverziózás, kereshetőség az analítika platform teljes spektrumán, általa a séma olvasás alapú adatfeldolozás és adathasználat. Jelen kontextusban metaadatnak nem kizáróan technikai attribútumok vannak jelen, hanem üzletiek, mint például az adat információérzékenységének szintje.
Feldolgozási réteg
Talán ez a legsokrétűbb rétege a lake house-nak, mert a különböző transzformációk legyenek azok technikaiak vagy üzletiek itt valósulnak meg. Ezen rétegben válik a nyers adat fogyaszthatóvá, informatívvá a felhasználó számára (számok és betűk együttes összefüggése adatalapú / adattámogatott vezetői döntéshozatalra alkalmassá válik).
Az adatfeldolgozási eljárásokban alkalmazott AWS szolgáltatás(ok) kiválasztását az adat jellege (stuktúrált vagy sem, hierachiába rendezett vagy sem) és annak áramlási sebessége nagyban magyarázzák.
SQL alapú feldolgozás – Redshift
A Masszívan Párhuzamos Feldolgozás (röviden MPP) egy adatbázis- és adattárháztechnológiai megközelítés, amely több processzort és tárolót használ fel az adatok nagy sebességű és hatékony feldolgozására. Ezt használja a Redshift. Az MPP architektúra különböző részekre bontja az adatfeldolgozási feladatokat, és ezeket párhuzamosan hajtja végre több processzoron ill. csomóponton.
Az alábbiakkal jellemzik a taglalt feldolgozási metódus:
- Csomópontok és Szegmensek: Az Amazon Redshift egy MPP adattárház, amely csomópontokból áll. Minden csomópont felelős egy részfeladatért és az adatok egy szegmenséért. Az MPP lehetővé teszi, hogy az adattárház egyszerre több feladaton dolgozzon, mivel minden csomópont a saját szegmensével foglalkozik.
- Elosztott adattárolás: Az adatokat az Amazon Redshift elosztott módon tárolja a csomópontok között. Ez azt jelenti, hogy az adatokat különböző csomópontokon tárolják, így a lekérdezések és feldolgozási feladatok párhuzamosan történhetnek.
- Szegmensek közötti paritás: Az MPP rendszerekben a szegmensek közötti paritás és egyensúly segít biztosítani, hogy a terhelés egyenletesen oszoljon el a csomópontok között. Ezenkívül a párhuzamos feldolgozásnak köszönhetően az adatok kezelése hatékonyabb és gyorsabb.
- Paralell lekérdezések: Az Amazon Redshift lehetővé teszi a párhuzamos lekérdezéseket, amelyeket minden csomóponton egyszerre hajt végre. Ez növeli a lekérdezések teljesítményét, különösen nagy adathalmazok esetén.
Az MPP elveket alkalmazó adattárházak, mint az Amazon Redshift, kiválóan alkalmasak nagy adatmennyiségek gyors és hatékony feldolgozására, és így ideálisak az analitikai és üzleti intelligencia feladatokra.
Big Data feldolgozás – EMR (Elastic Map Reduce) vagy Glue
Az AWS Glue és az Elastic MapReduce (EMR) kombinációja alkalmazható adatok feldolgozására. Az AWS Glue egy teljesen menedzselt adatfeldolgozási szolgáltatás, amely lehetővé teszi az adatforrások közötti integrációt és az adatok előkészítését a Data Lake House-ban. A Glue segítségével könnyedén definiálhatók az adatforrások séma-átalakítási és összekapcsolási logikái, így egyszerűen tisztíthatók és strukturálttá alakíthatók az adatok.
Az EMR pedig rugalmas és skálázható infrastruktúrát biztosít úgy nevezett “instance fleet”-ek létrehozásával. A Hadoop osztott fájlrendszer (HDFS) és a Spark (keretrendszer) használatával az EMR lehetővé teszi a párhuzamos feldolgozást, ami hatékony adatfeldolgozást eredményez származzon a feldolgozandó adat S3-ból vagy Redshfit-ből. Az EMR klasztereket hoz létre, amelyek skálázhatóak az adatmennyiség és a feldolgozási igények függvényében.
Az AWS Glue és EMR kombinált alkalmazásával az adatok könnyedén mozgathatók és feldolgozhatóak. Az adatforrások közötti integráció és előkészítés során a Glue segít az adatok strukturálttá alakításában, katalogizálásában, majd az EMR rugalmas infrastruktúrája lehetővé teszi a nagyobb léptékű adatfeldolgozást és adatelőkészítést gépi tanuló algoritmusok számára.
Streaming feldolgozás – Kinesis
Erra a feldolgozási módra van szükség azokban az esetekben, amikor nagy volumenű (nem nagy méretű) adatokat szükséges validálni, tisztítani vagy dúsítani, esetleg egyből a lake house fogyasztói rétegébe tölteni, mindezt rövid idő alatt, azaz stream-elni.
Adott a lehetőség, hogy más AWS szolgáltatásokkal integrálva közel valós időben áramoljanak az adatok a forrástól a lake house bármely rétegéig. Ezt a Kinesis Data Stream, Kinesis Firehose, Kinesis Analytics szolgáltatásokkal érhetjük el használati esetnek megfelelően kombinálva a felsoroltakat a korábbiakban már említett vagy taglalt EMR, Glue, Redshift szolgáltatásokkal. Az integrítást biztosító interfészek alkalmazásával.
A Kinesis Data Streams a folyamatos adatgyűjtésért és párhuzamos feldolgozásért felelős, míg a Kinesis Firehose az adatok automatizált továbbítását és átalakítását látja el a kívánt tárhelyekre.
Fogyasztói / Applikációs réteg
Az architektúrának az előnyei között említett szervezeten belüli adat demokraitizálódás a fogyasztói vagy ú.n. applikációs rétegben manifesztálódik. A vállalat különböző felhasználói csoportjainak használati eseteit lefedi, legyen az üzleti intelligencia (BI) vagy gépi tanulási (ML). Ebben a rétegben használt AWS szolgáltatásokkal könnyedén átjárható a lake house relációs, struktúrált és részben struktúrált adatokért tárolási formátumtól függetlenül (AVRO, Parquet, ORC, JSON).
Interaktív lekérdezések
Redshift a Redshift Spectrummal együtt, Athena –val könnyedén lekérdezhetőek az S3-ban tárolt adatok, mert mindkét szolgáltatás egyazon metaadat katalóguson osztozik.
Athena egy serverless szolgáltatás melynek költségét a lekérdezett adatok mennyisége határoz meg. Általa lekérdezhetőek a katalogizált adatok a nélkül, hogy bármennyit be kellene tölteni egy adatbázisba. Az adatmozgatás nélküli lekérdezés a közös metaadat katalógus által biztosított, megteremtve a képességet akár a Redshift-ben normalizált relációs adatok és operatív adatbázisokban található rekordok összekötésére.
A Redshift hasonlóan futtathatóak lekérdezések, azonban másra tervezett és implementált szolgáltatás. Főként erőforrás igényes analítikai folyamatok végrehajátására (OLAP) használt. Komplexebb lekérdezések cache-elésére és párhuzamos skálázásra is lehetőséget ad. Ameddig pedig nem ismertek a lekérdezések performancia igényei, addig érdemes lehet a serverless példányát igénybe venni.
Gépi tanulás
Haladó analitikát alkalmazó vállalatok data scientist-jeinek is teret ad a DLH, hogy a korábban felsorolt tárolási rétegekből akár együttesen tanítási adathalmazokat készítsenek elő
- használva a metaadat katalógust
- felfedezve az adathalmazokat Redshift, Athena lekérdezésekkel
- EMR (Spark) szolgáltatással összefűzve és transzformálva
A transzformációkat követően előállított oktatási adatokat SageMaker-ben kezdetét veheti a a gépi tanuló algoritmusok alkalmazása. SageMaker-ben megtalálhatók széleskörben alkalmazott keretrendszerek pl. Tensorflow, MXNet, PyTorch, Keras stb. Beépített modellek mellett egyedi megoldások is alkalmazhatóak.
Üzleti intelligencia
Az adatokból információ nyerhető ki dashboard-on szemléltetett elemzésekkel. A már említett SageMaker gépi tanulási platformmal könnyedén összekötehtő, további információval dúsítva egyes vizualizált elemzéseket.
A vizualizált adatok QuickSight-tal jeleníthetők meg AWS natívan, és be is ágyazhatók különböző weboldalakra, applikációkba.
Több tízezer felhasználóig skálázható “in-memory” cach-ének köszönhetően. Gépi tanulás által fel van vértezve előrejelző és anomália felismerő modellekkel.
Hogyan tovább / Hogyan fogjak az építkezéshez?
Az AWS platformon való Data Lake House építése több lépésből áll. Az alábbiakban megtalálhatók az alapvető lépések, amelyek segíthetnek a Data Lake House megvalósításában az AWS felhőplatformon:
- Követelmények és célok meghatározása:
- Az üzleti követelmények és célok azonosítása, amelyeket egy analítika platform megvalósításával kívánunk elérni.
- Adatforrások, az adatstruktúrák, és annak meghatározása, hogy milyen típusú adatfeldolgozásra van szükség.
- AWS Account és IAM felhasználók kezelése
- Fejlesztési környezet és hálózati szeparációk megtervezése
- Access Management-et megtervezni azaz felhasználói köröket és jogosultságokat a biztonságos adatkezeléshez
- Adattárolás megtervezése
- Adattárolási megoldások kiválasztása az AWS-ben, például az Amazon S3-t, amely ideális egy Data Lake House esetében.
- Strukturálni az adattárolási rendszert, például mappastruktúrával vagy adatpartíciózást az adatok szervezéséhez.
- Adatgyűjtés és bevitel
- Adatbeviteli szolgáltatások használatával, mint az AWS Kinesis Data Streams vagy Kinesis Firehose, az adatok folyamatos gyűjtéséhez és beviteléhez integráljuk a forrásrendszereket annak függvényében, hogy az adatokat milyen gyakorisággal szükséges gyűjteni.
- Adattranszformáció és előkészítés
- AWS Glue szolgáltatással az adatok automatizált transzformálása és előkészítése
- Adatséma módosítás, adattisztítás, és adatbázis indexelés történik ebben a lépésben
- Iparági adatmodell implementálásával
- Adatfogyasztás és elemzés
- Amazon Athena, Redshift vagy a QuickSight az adatok lekérdezéséhez és elemzéséhez.
- Adattöltések konfigurálása a valós idejű adatfeldolgozáshoz az AWS Kinesis szolgáltatással
- Automatizálás és monitorozás:
- Adatfolyamatok automatizálhatók és karbantarthatók az AWS egyéb szolgáltatásaival, mint például a Step Functions vagy a Lambda segítségével.
- Adatfolyamatok monitorozhatók a AWS CloudWatch-csal és más monitoring eszközökkel (pl. CloudTrail), akár az adattisztaság nyomonkövetéséhez
- Biztonság és hozzáféréskezelés:
- A szükséges biztonsági intézkedések beállítása: hozzáféréskezelést, titkosítást és auditálást.
- AWS Identity and Access Management (IAM) jogosultságok lefedése az adatok védelmére.
- Mondhatni ez az egyik legfontosabb része egy modern analítika platformnak, mivel nagy figyelmet kell, hogy kapjon az authorizáció, az adatokhoz való hozzáférés menedzselése és monitorozása.
- Dokumentáció és tréning:
- Data Lake House architektúra és működési / működtetési folyamatok írott formában jelenjenek meg
- Tréningek szervezésével a felhasználó körök számára az AWS szolgáltatások használatáról, legújabb eljárásokról és legjobb gyakorlatokról stabilabbá tehető az üzletfolytonosság.
Összefoglaló
A taglalt fejezetekben, pontokban madártávlatból bemutatásra került egy modern analitika architektúrális megközelítése az adatok bekerüléséről, átalakításáról és hasznosítási lehetőségeiről AWS-en (a teljesség igénye nélkül).
Ha egy szervezet tervezi vagy gondolkodik a digitális és analitikai transzformáción, a Data Lake House megközelítés megfontolandó, amennyiben szeretne:
- egy integrált és automatizálható platformot, ezáltal minimális implementációs kockázatot és rövid “time to market”-et elérni
- kicsiben elindítható, serverless, minimális költséggel járó, nagymértékben és azonnal skálázható szolgáltatást, amely alkalmazkodik az adattöltések erőforrásigényéhez
- sokféle szolgáltatást, rugalmas, innovatív, új iparági trendeket kvázi azonnal elérni
A vállalat méretétől függetlenül létrehozhatók a rétegek a rugalmas skálázhatóságnak köszönhetően. Az ördög a részletekben rejlík, ezáltal a felvonultatott szolgáltatások mögötti technikai vagy felhasználói/üzleti logikában rejlik.
Abban az esetben, ha támogatásra vagy segítségre van szüksége az implementációhoz, keressen minket az info@tc2.ai email címen.
